
Sponsors:
- National Science Foundation, grants numbers CCF-0444405,
CNS-0406341,
CCR-0325207,
CNS-0551639,
CNS-0551551) - Department of Energy, award number DE-FC02-01ER25485
- Intel Corporation
Project Team Members:
Northwestern University
- Jay Pisharath
- Ying Liu
- Berkin Ozisikyilmaz
- Ramanathan Narayanan
- Wei-keng Liao
- Gokhan Memik
- Alok Choudhary
Intel Architecture Research Lab



Design, Development and Evaluation of High Performance Data Mining Systems
Project Goals:
With the enhanced features in recent computer systems, increasingly larger amounts of data are being accumulated in various fields. The collected data is growing exponentially every year, and it becomes increasingly necessary to use automated tools in order to extract precise and useful information from the collected data. Data mining is a powerful tool that enables one to achieve this. Data mining programs have become essential tools in many domains including business (marketing, customer relationship management, scoring and risk management, fraud detection), science (astrophysics, climate modeling, particle physics), biotechnology (understanding diseases, protein identification, drug discovery, personalized medicine), and other fields like internet searches, multimedia, security, etc.
All data mining tools are sophisticated, complex and are increasingly becoming performance-hungry due to the amount of data that they require to handle. One important obstacle that has to be addressed is the fact that the performance of computer systems is improving at a slower rate compared to the increase in the requirements of data mining applications. Recent trends suggest that the system performance (based on data-intensive workloads) has been improving at a rate of 10-15% per year, whereas, the volume of data that is collected more than doubles every year. Existing data mining tools are not able to run efficiently on existing systems. Researchers have focused on efficient implementations of different data mining algorithms by proposing numerous algorithmic optimizations and by proposing parallel and distributed versions of these algorithms. However, even such highly optimized versions of algorithms have long run times. In this project, we try to close this gap between the growing demands of data mining and the performance of computing systems.
Methodology:
In order to close the gap between data mining applications and computing systems, we aim to do the following tasks:
- Develop an understanding of the characteristics of data mining applications and understand the way these applications get mapped on to existing computing systems. This information about the characteristics can then be utilized during the implementation of the algorithms and the design/setup of the computing systems.
- Identify the actual architectural bottlenecks, and design new (or adapt existing) computer architectures to data mining applications. Simultaneously, algorithms also need to be adapted to the revised requirements of applications and architectures.
The ultimate goal of this project is to enable a smooth integration of data mining applications into computer systems. Futuristic data mining systems would be designed with an objective to provide high performance, with the respective compute engines being able to host appropriate data mining algorithms in an efficient fashion. Note that specific hints would be provided for algorithm writers to efficiently (rather fully) utilize such systems. Figure 1 shows our project goals.
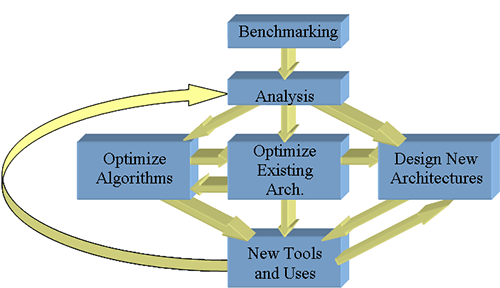
Figure 1. Our approach to high-performance data mining systems design
Accomplishments:
We began by attacking task (i) of our goals. We try to achieve this goal by performing a detailed characterization of representative data mining programs. Such a characterization needs to done from both the hardware and software perspectives. For this, we first study several widely-used data mining algorithms from multiple categories and, then, use them to design NU-MineBench, a benchmarking suite containing representative data mining applications. NU-MineBench suite includes two classification, two association rule mining, and four clustering applications. We evaluate the NU-MineBench applications on uniprocessor, shared memory and distributed memory parallel machines. We then analyze important performance characteristics of these applications. This characterization evaluates the applications based on a variety of the measure of interest, ranging from execution times, operating system overheads to hardware measure like processor utilization, cache behavior, memory access statistics, and bus usage. Since scalability is deemed to be an important (and unavoidable) requirement in future systems, we also perform a scalability study of our benchmark suite by varying both the input data sets and the number of processors used for execution. Parallel and distributed versions of these algorithms were developed and implemented to perform this scalability study. We believe that this large information about the characteristics of representative data mining applications can aid designers of future systems as well as programmers of new data mining algorithms to achieve better system and algorithmic performance. NU-MineBench is available for public use and can be found at this site in the Downloads section. The related publications can be found in the Publications section.
Publications:
- Ramanathan Narayanan, Berkin Ozisikyilmaz, Joseph Zambreno, Jayaprakash Pisharath, Gokhan Memik, and Alok Choudhary. MineBench: A Benchmark Suite for Data Mining Workloads. In Proceedings of IEEE International Symposium on Workload Characterization (IISWC), October 2006. (pdf)
- Berkin Ozisikyilmaz, Ramanathan Narayanan, Joseph Zambreno, Gokhan Memik, and Alok Choudhary. An Architectural Characterization Study of Data Mining and Bioinformatics Workloads. In Proceedings of IEEE International Symposium on Workload Characterization (IISWC), October 2006. (pdf)
- Jayaprakash Pisharath, Josep Zambreno, Berkin Ozisikyilmaz, and Alok Choudhary/ Accelerating Data Mining Workloads: Current Approaches and Future Challenges in System Architecture Design. In Proceedings of the 9th International Workshop on High Performance and Distributed Mining (HPDM), April 2006. (pdf)
- Joseph Zambreno, Berkin Ozisikyilmaz, Jayaprakash Pisharath, Gokhan Memik, and Alok Choudhary. Performance Characterization of Data Mining Applications using MineBench. In Proceedings of the 9th Workshop on computer Architecture Evaluation using Commercial Workloads (CAECW-9), February 2006. (pdf)
- Jayaprakash Pisharath and Alok Choudhary. Design of a Hardware Accelerator for Density Based Clustering Applications. In Proceedings of the International Conference on Application-specific Systems, Architectures and Processors (ASAP), July 2005. (unavailable)
- Ying Liu, Jayaprakash Pisharath, Wei-keng Liao, Gokhan Memik, Alok Choudhary, and Pradeep Dubey. Performance Evaluation and Characterization of Scalable Data Mining Algorithms. In Proceedings of the 16th International Conference on Parallel and Distributed Computing and Systems (PDCS), November 2004. (pdf) EXTENDED VERSION (NU-MineBench Technical Report): Jayaprakash Pisharath, Ying Liu, Wei-keng Liao, Gokhan Memik, Alok Choudhary, and Pradeep Dubey. NU-MineBench: Understanding the Performance and Scalability Characteristics of Data Mining Algorithms. Technical Report CUCIS-2004-05-001, May 2004. (CUCIS-2004-05-001.pdf)
- Ying Liu, Wei-keng Liao, and Alok Choudhary. Design and Evaluation of a Parallel HOP Clustering Algorithm for Cosmological Simulation. In Proceedings of the 17th International Parallel and Distributed Processing Symposium (IPDPS), pp. 82-89, April 2003. (pdf)
Presentation Slides:
- Data Mining Benchmark - NU-MineBench Presentation, Speaker: Alok Choudhary, Location: Intel Corporation (MRL), Date: March 15, 2004
NU-MineBench Software:
- NU-MineBench is a software package containing the data mining algorithms studied in this research.