
Sponsor:
- DoD Modernization Program
Project Team Members:
Northwestern University
- Prof. Alok Choudhary
- Prof. Wei-keng Liao
Syracuse University
- Prof. Donald Weiner
- Prof. Pramod Varshney
Air Force Research Labs
- Dr. Richard Linerman
- Dr. Mark Linerman
Performance Results of Parallel Pipeline STAP Implementation
The parallelization of the STAP application based on our parallel pipeline system model was implemented on the Intel Paragon at the Air Force Research Laboratory, IBM SP at Argonne National Laboratory, and SGI Origin at Northwestern University.
Each CPI complex data cube is a 512 x 16 x 128 three-dimensional array. A total of 25 CPIs were generated as inputs to the parallel pipeline system. In each task, timing results for processing one CPI data cube were obtained by accumulating the execution time for the middle 20 CPIs and then averaging it. Timing results presented in this paper do not include the effect of initial setup (first 3 CPIs) and final stage (last 2 CPIs). Each task in the pipeline contains three parts: receiving data from the previous task, main computation, and sending results to the next task. Performance results are measured separately for these three parts, namely receive time, compute time, and send time. Since the multiple thread strategy is implemented in the compute phase only, we first discuss the compute time for each task in the pipeline and then present the performance results for the integrated pipeline system.
| AFRL Paragon | ANL IBM SP | NWU SGI Origin | |
|---|---|---|---|
| CPU Type | i860 TISC | P2SC | MIPS R10000 |
| RAM (MByte) | 64 | 256 | 1024 |
| MFLOPS / proc | 100 | 480 | 390 |
| MHz / proc | 40 | 120 | 195 |
| No. nodes | 232 | 80 | 8 |
| No. proc / node | 3 | 1 | 1 |
| Execution mode | dedicate | dedicate | time shared |
| Math Library | CLASSPACK | ESSL | SCSL |
Timing of Compute Phases on Intel Paragon
The task of computing hard weights is the most computationally demanding task. The Doppler filter processing task is the second most demanding task. Naturally, more compute nodes are assigned to these two tasks in order to obtain a good performance. For each task in the STAP algorithm, parallelization was done by evenly dividing computational load across compute nodes assigned. Figure 1 gives the performance results for compute phases on the AFRL Intel Paragon. It includes the execution time, the corresponding speedup, and the threading speedups of using two threads over non-threaded implementation, all as functions of numbers of compute nodes. For each task, we obtained linear speedups on both using two threads and single thread. From Figure 1(b), the speedups when using two threads are approximately the same as using single thread.
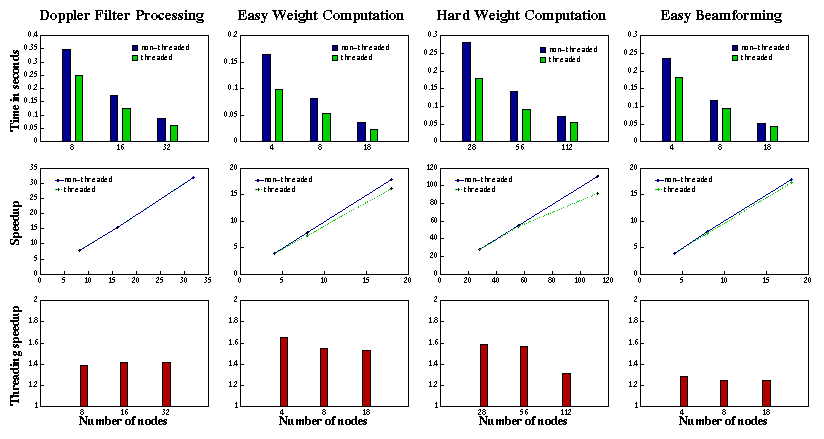
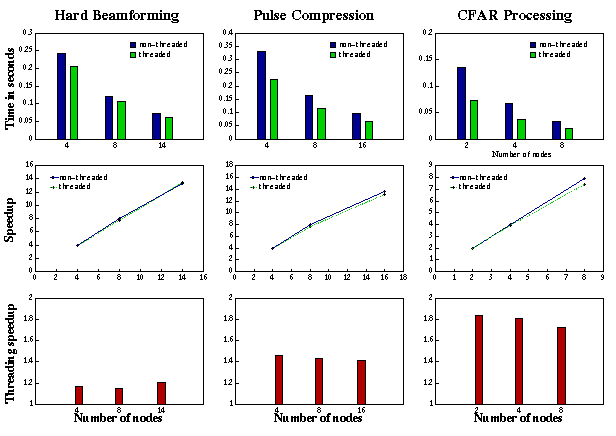
Assuming that the execution time of a non-threaded implementation of a task is t1 and the execution time of its threaded implementation is t2, we define the threading speedup for threaded over non-threaded implementation as s = t1 / t2 Since two processors are employed in the threaded implementation, we have t1 / 2 <= t2 <= t1 and therefore 1 <= s <= 2. The threading speedups for all compute phases are given in Figure 1(c). By running on two processors at the same time, the two threaded STAP code ideally can have a threading speedup of 2. However, in most cases, the actual threading speedups do not approach this ideal value. This may be caused by the limitation of implementation of operating system, OSF/1, and the implementation of linked thread-safe libraries. On an Intel Paragon MP system, scheduling of threads is handled by the operating system kernel. Users cannot have control over or get information about which processor runs which thread. On the other hand, the implementation of thread-safe versions of linked libraries most likely contains overheads of concurrent read/write operations when multiple threads are taken into consideration. Although each thread in a process executes independently, it shares resources with other threads, for example, the memory. Concurrent read and write operations prevent the threaded implementation from obtaining a linear speedup, even if two processors are used concurrently.
Integrated System Performance Evaluation
Timing Results on IBM SP
Click here to go back