
Sponsor:
- DoD Modernization Program
Project Team Members:
Northwestern University
- Prof. Alok Choudhary
- Prof. Wei-keng Liao
Syracuse University
- Prof. Donald Weiner
- Prof. Pramod Varshney
Air Force Research Labs
- Dr. Richard Linerman
- Dr. Mark Linerman
Multi-Threading Implementation on Intel Paragon SMP Nodes
We implemented our parallel pipeline model of the STAP algorithm on the Intel Paragon XP/S parallel computer located at Air Force Research Laboratory in Rome NY. The compute partition of this machine consists of 307 MP nodes, each with 64 MByte RAM. All 307 MP nodes are connected by a high-speed node interconnect network and are configured in a two-dimensional mesh. Of the 307 MP nodes, 232 are general compute nodes with three i860 processors on each compute node board. Each of the three processors has its own private cache memory but shares the main memory with the other two processors. The operating system is a version of UNIX OSF/1. By running this operating system, the three processors in each compute node are configured with two processors as general application processors and one processor as message coprocessor which is dedicated to message passing. Multi-threaded programming environment is supported on a Paragon system 1. The threads are implemented as POSIX threads} which are based on the POSIX Threads Extension [C language] P1003.4a/D4 (Draft 4), August 1990. Therefore, the programs that uses POSIX threads} may not be portable to other systems.
Since two out of the three processors in the Paragon MP system are configured as general application processors, threads in a multi-threaded program on the MP system can run on either of the two application processors. Each thread runs independently, but shares resources with other threads. For example, all the threads in a single process share the main memory. Each compute node acts just like a parallel shared memory system with two processors. Ideally, if multi-threaded programs have no concurrent write operations, a speedup of 2 can be expected by using threads on a compute node of the Paragon MP system.
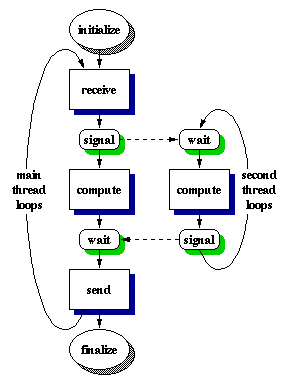
Figure 1. Implementation of two threads in the compute phase. The main thread signals the second thread to perform its computation. After completion of its computation, the second thread signals back to the main thread.
Two threads implementation in compute phases
The Intel Paragon at the AFRL is an MP system which has three processors on each compute node board. In each compute node, two out of the three processors are configured as general processors to run application code while the third as a message coprocessor which is dedicated to message passing. With this configuration, only compute phase for each task in our parallel pipeline system is implemented with threads. The reason for not implementing threads in communication phases is that the Paragon message-passing library is not thread-safe. Also, if more than one thread performs message passing, the message-passing performance may degrade and results may be incorrect. The message passing thread can be the main thread or any other thread. However, a thread other than the main thread will experience higher message latency than the main thread. Besides, one processor has already been configured as message coprocessor which is dedicated to message passing and the communication performance has been sufficiently improved on the Paragon system.Since there are only two application processors in each compute node, each compute phase in every task will have two threads implemented. For each task, the main thread in the compute phase sends a signal to the second thread when the input data is ready at the receive phase. Both threads then perform the computation on two processors concurrently. Once the second thread completes its computation, it signals the main thread that its output data is ready for the main thread to start the send phase. While the main thread is performing the message passing calls, the second thread is waiting for its input signal from the main thread. These two signal operations involve two synchronizations of two threads using a mutually exclusive access semaphore. Figure 1 gives the execution flows of two threads in the compute phase.
Reference:
Click here to go back