
Sponsor:
This work is supported in part by Sandia National Laboratories, NSF award numbers CCF-0621443, OCI-0724599, CCF-0833131, CNS-0830927, IIS-0905205, OCI-0956311, CCF-0938000, CCF-1043085, CCF-1029166, and OCI-1144061, and in part by DOE grants DE-FC02-07ER25808, DE-FG02-08ER25848, DE-SC0001283, DE-SC0005309, DE-SC0005340, and DE-SC0007456.Project Team Members:
Northwestern University
- Alok Choudhary
- Wei-keng Liao
- Ankit Agrawal
- Saba Sehrish
- Seung Woo Son
- Arifa Nisar (graduated)
- Avery Ching (graduated)
- Kenin Coloma (graduated)
Sandia National Laboratories
- Lee Ward
Argonne National Laboratories
- Rob Ross
- Rajeev Thakur
- Rob Latham



Scalable Optimizations for MPI-IO
Objectives:
Parallel file access has been an active research topic in recent years. Many efforts have been contributed in both software development and hardware design to improve the I/O bandwidth. However, most of the works were investigating the file access patterns when no overlapping access occurs in the concurrent I/O requests. In this project, we address the overlapping I/O problem that exists in today’s parallel computing environments by considering the requirements of MPI I/O semantics on I/O atomicity and file consistency. Traditional solution for enforcing correct MPI I/O semantics uses byte-range file locking which can easily serialize the I/O parallelism. Our work for designing scalable approach consists of the following three tasks:- I/O delegation
- Optimal file domain partitioning methods for collective I/O
- Client-side file caching sub-system at MPI I/O level
- Coherent cache access for collective MPI I/O
- Scalable implementation for MPI I/O atomicity
I/O delegation
Massively parallel applications often require periodic data checkpointing for program restart and post-run data analysis. Although high performance computing systems provide massive parallelism and computing power to fulfill the crucial requirements of the scientific applications, the I/O tasks of high-end applications do not scale. Strict data consistency semantics adopted from traditional file systems are inadequate for homogeneous parallel computing platforms. For high performance parallel applications independent I/O is critical, particularly if checkpointing data are dynamically created or irregularly partitioned. In particular, parallel programs generating a large number of unrelated I/O accesses on large-scale systems often face serious I/O serializations introduced by lock contention and conflicts at file system layer. As these applications may not be able to utilize the I/O optimizations requiring process synchronization, they pose a great challenge for parallel I/O architecture and software designs. Our I/O delegation is an I/O mechanism to bridge the gap between scientific applications and parallel storage systems. A static file domain partitioning method is used to align the I/O requests and produce a client-server mapping that minimizes the file lock acquisition costs and eliminates the lock contention. Our performance evaluations of production application I/O kernels demonstrate scalable performance and achieve high I/O bandwidths.Optimal file domain partitioning methods for collective I/O
MPI collective I/O has been an effective method for parallel shared-file access and maintaining the canonical orders of structured data in files. Its implementation commonly uses a two-phase I/O strategy that partitions a file into disjoint file domains, assigns each domain to a unique process, redistributes the I/O data based on their locations in the domains, and has each process perform I/O for the assigned domain. The partitioning quality determines the maximal performance achievable by the underlying file system, as the shared-file I/O has long been impeded by the cost of file system's data consistency control, particularly due to conflicted locks. This work presents a set of file domain partitioning methods designed to reduce lock conflicts under the extent-based file locking protocol. Experiments from four I/O benchmarks on the IBM GPFS and Lustre parallel file systems show that the partitioning method producing minimum lock conflicts wins the highest performance. The benefit of removing conflicted locks can be so significant that more than thirty times of write bandwidth differences are observed between the best and worst methods.Client-side file caching sub-system at MPI I/O level
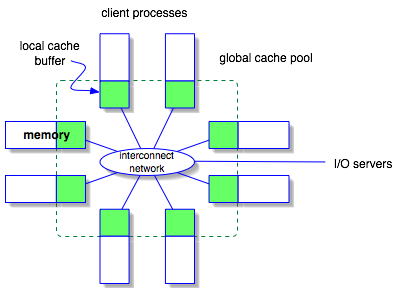
Parallel file subsystems in today's high-performance computers adopt many I/O optimization strategies that were designed for distributed systems. These strategies, for instance client-side file caching, treat each I/O request process independently, due to the consideration that clients are unlikely related with each other in a distributed environment. However, it is inadequate to apply such strategies directly in the high-performance computers where most of the I/O requests come from the processes that work on the same parallel applications. We believe that client-side caching could perform more effectively if the caching sub-system is aware of the process scope of an application and regards all the application processes as a single client.We design a client-side file caching sub-system that coordinates the MPI application processes to manage cache data and achieve cache coherence without involving the I/O servers. We consider all processes that run the same application as a single client and file caching is performed and managed by the clients only. This idea is illustrated in Figure 2. We first logically divide a file into blocks of the same size in which each block represents an indivisible page that can be cached in a process's local memory. Cache metadata describing the caching status of these file blocks is distributed in a round-robin fashion among the processes that together open the file. Since cache data and metadata are distributed among processes, each process must be able to response to remote requests for accessing to data stored locally. For MPI collective I/O where all processes must be synchronized, fulfilling remote requests can be achieved by first making each request known to all processes and, then, using inter-process communication to deliver data to the requesting processes. On the contrary, MPI independent I/O is asynchronous which makes it difficult for one process to explicitly receive remote requests. Therefore, our design needs a mechanism to allow a process to access to remote memory without interrupting the execution of the remote processes. To demonstrate this idea, we proposed two implementations: using a client I/O thread and using MPI remote memory access utility.
Coherent cache access for collective MPI I/O
In this task, we consider the I/O patterns with the overlaps across a sequence of collective MPI I/O operations. This subsequent overlapping I/O happens when the same data accessed by an earlier MPI I/O operation is accessed later by another I/O operation. On parallel machines that perform client-side file caching, the subsequent overlapping I/O can lead to the {\it cache coherence} problem. Incoherent cache occurs when multiple copies of the same data are stored at different clients and a change to one copy does not propagate to others in time, leaving the cached data in an incoherent state. Traditionally, the file consistency problem can be solved by using byte-range file locking, because once a file region is locked, any read/write operations will go directly to the I/O servers. However, this approach can significantly increase the communication overhead between clients and servers.We propose a scalable approach, called persistent file domain (PDF), that reuses the file access information from the preceding MPI I/O operations to guide the subsequent I/O to the processes that hold the most up-to-date cache. In ROMIO, a popular MPI implementation developed at Argonne National Laboratories (ANL), the life of the file domains only spans a single MPI collective I/O call. Our persistent file domain approach, on the contrary, preserves the file domains for the subsequent I/O operations to avoid accessing to obsolete cache data. We further analyze three domain assignment strategies for the PFD method. User specified stripe size provides users an option to supply a customized stripe size through an MPI_Info object to the PFD. The PFD uses it to statically assign the file domains by cyclically striping the file across all the processes that open the file collectively. File view based assignment automatically calculates a new PFD assignment each time a new MPI file view is set. Once a file is opened and the file views are set, the stripe unit size is computed by dividing the aggregate access region of the first collective I/O by the number of the processes. Aggregate access region based assignment re-calculates the PFD when the size of aggregate access region is changed. The size of aggregate access region will change in two situations: 1) the file view is changed; and 2) the argument of I/O buffer derived data type in the collective I/O call is changed.
Scalable implementation for MPI I/O atomicity
I/O atomicity is referred to as the outcome of the overlapped regions, both in the file and process's memory, from a concurrent overlapping I/O operation. Atomic I/O indicates that all the overlaps between two or more processes come from one of the processes only. While the POSIX standard demands the atomicity for individual read/write calls, the MPI semantics require the atomicity in the granularity of MPI I/O call. Since MPI allows a process to access multiple non-contiguous file regions in a single I/O call, guarantee of atomic I/O in each contiguous region is not sufficient to achieve the results required by the MPI standard. Figure 1 shows an example of a concurrent write operation from two MPI processes in both atomic and non-atomic modes. A two-dimensional array is partitioned between two processes with a few columns overlapped. To gain exclusive access to a file region, most of the file systems provide byte-range file locking, which can be used to achieve the desired I/O atomicity. However, file locking can potentially serialize the I/O parallelism.
We propose two scalable methods for MPI atomicity:
graph coloring and process-rank ordering.
These two methods allow the MPI processes to negotiate with each other
for the
access orders when overlaps occur. For graph-coloring method, wefirst
divide the processes into k groups (colors) in which no two processes
in a group overlap, then the concurrent write is carried out in k
steps. This graph-coloring approach can maintain a degree of I/O
parallelism if k < P, the number of processes. For process-rank
ordering method, we let the highest ranked processes win whenever an
overlap
occurs between two or more processes. As a result, the lower ranking
processes modify their requests by subtracting the overlaps. This
approach can fulfill the atomicity requirement, because data resulting
in any overlap of two or more processes will come from the process with
the highest rank.
As described in the previous section, the atomicity semantics do not
specify exactly which process's data shall appear in the overlap. As
long as the data of the overlap all come from the same process, it is
considered an atomic I/O.
Related Links
- ROMIO at Argonne National Laboratory
Publications:
- Rob Latham, Chris Daley, Wei-keng Liao, Kui Gao, Rob Ross, Anshu Dubey and Alok Choudhary. A case study for scientific I/O: improving the FLASH astrophysics code.. Computer and Scientific Discovery, 5, March 2012.
- Chen Jin, Saba Sehrish, Wei-keng Liao, Alok Choudhary, and Karen Schuchardt. Improving the Average Response Time in Collective I/O. In the 18th EuroMPI Conference, September 2011.
- Seong Jo Kim, Yuanrui Zhang, Seung Woo Son, Ramya Prabhakar, Mahmut Kandemir, Christina Patrick, Wei-keng Liao, and Alok Choudhary. Automated Tracing of I/O Stack. In the 17th EuroMPI Conference, September 2010.
- Seung Woo Son, Samuel Lang, Philip Carns, Robert Ross, Rajeev Thakur, Berkin Ozisikyilmaz, Prabhat Kumar, Wei-keng Liao, and Alok Choudhary. Enabling Active Storage on Parallel I/O Software Stacks. In the 26th IEEE Symposium on Massive Storage Systems and Technologies, May 2010.
- Florin Isaila, Francisco Javier Garcia Blas, Jesus Carretero, Wei-keng Liao, and Alok Choudhary. A Scalable Message Passing Interface Implementation of an Ad-Hoc Parallel I/O System. International Journal of High Performance Computing Applications, 24(2):164-184, 2010.
- Robert Ross, Alok Choudhary, Garth Gibson, and Wei-keng Liao. Book Chapter 2: Parallel Data Storage and Access. In Scientific Data Management: Challenges, Technology, and Deployment, Chapman & Hall/CRC Computational Science Series, CRC Press, December 2009.
- Alok Choudhary, Wei-keng Liao, Kui Gao, Arifa Nisar, Robert Ross, Rajeev Thakur, and Robert Latham. Scalable I/O and Analytics. Journal of Physics: Conference Series, 180(012048), August 2009.
- Jacqueline Chen, Alok Choudhary, Bronis de Supinski, Matthew DeVries, Evatt Hawkes, Scott Klasky, Wei-Keng Liao, Kwan-Liu Ma, John Mellor-Crummy, Norbert Podhorski, Ramanan Sankaran, Sameer Shende, and Chun Sang Yoo. Terascale Direct Numerical Simulations of Turbulent Combustion Using S3D. Journal of Computational Science & Discovery, 2(015001), 2009.
- Avery Ching, Kenin Coloma, Arifa Nisar, Wei-keng Liao, and Alok Choudhary. Book Chapter: Distributed File Systems. In Wiley Encyclopedia of Computer Science and Engineering, John Wiley & Sons, Inc., January 2009.
- Florin Isaila, Francisco Javier Garcia Blas, Jesus Carretero, Wei-keng Liao, and Alok Choudhary. AHPIOS: An MPI-based Ad-hoc Parallel I/O System. In the 14th International Conference on Parallel and Distributed Systems, December 2008.
- Wei-keng Liao and Alok Choudhary. Dynamically Adapting File Domain Partitioning Methods for Collective I/O Based on Underlying Parallel File System Locking Protocols. In Proceedings of the International Conference for High Performance Computing Networking, Storage and Analysis, November 2008.
- Arifa Nisar, Wei-keng Liao, and Alok Choudhary. Scaling Parallel I/O Performance Through I/O Delegate and Caching System. In Proceedings of the International Conference for High Performance Computing Networking, Storage and Analysis, November 2008.
- Avery Ching, Kenin Coloma, Jianwei Li, Alok Choudhary, and Wei-keng Liao. High-Performance Techniques for Parallel I/O. In Handbook of Parallel Computing: Models, Algorithms, and Applications, CRC Press, December 2007.
- Avery Ching, Robert Ross, Wei-keng Liao, Lee Ward, and Alok Choudhary. Noncontiguous Locking Techniques for Parallel File Systems. In Proceedings of Supercomputing, November 2007.
- Wei-keng Liao, Avery Ching, Kenin Coloma, Alok Choudhary, Ramanan Sankaran,, and Scott Klasky. Using MPI File Caching to Improve Parallel Write Performance for Large-scale Scientific Applications. In Proceedings of the International Conference for High Performance Computing Networking, Storage and Analysis, November 2007.
- S. W. Son, G. Chen, O. Ozturk, Mahmut Kandemir, and Alok Choudhary. Compiler-directed Energy Optimization for Parallel Disk Based Systems. IEEE Transactions on Parallel and Distributed Systems (TPDS), 18(9):1241–1257, September 2007.
- Wei-keng Liao, Kenin Coloma, Alok Choudhary, and Lee Ward. Cooperative Client-side File Caching for MPI Applications. International Journal of High Performance Computing Applications, 21(2):144-154, May 2007.
- Kenin Coloma, Avery Ching, Alok Choudhary, Wei-keng Liao, Robert Ross, Rajeev Thakur, and Lee Ward. A New Flexible MPI Collective I/O Implementation. In IEEE Conference on Cluster Computing, March 2007.
- Wei-keng Liao, Avery Ching, Kenin Coloma, and Alok Choudhary. Improving MPI Independent Write Performance Using a Two-stage Write-behind Buffering Method. In NSF Next Generation Software Program Workshop in the Proceedings of the International Parallel and Distributed Processing Symposium, March 2007.
- Wei-keng Liao, Avery Ching, Kenin Coloma, Alok Choudhary, and Lee Ward. Implementation and Evaluation of Client-side File Caching for MPI-IO. In Proceedings of the International Parallel and Distributed Processing Symposium, March 2007.
- Avery Ching, Wu-chun Feng, Heshan Lin, Xiaosong Ma, and Alok Choudhary. Exploring I/O Strategies for Parallel Sequence Database Search Tools with S3aSim. In Proceedings of the 15th International Symposium on High Performance Distributed Computing (HPDC), June 2006.
- Peter Aarestad, Avery Ching, George Thiruvathukal, and Alok Choudhary. Scalable Approaches for Supporting MPI-IO Atomicity. In Proceedings of the 6th International Symposium on Cluster Computing and the Grid (CCGrid), May 2006.
- Avery Ching, Alok Choudhary, Wei-keng Liao, Lee Ward, and Neil Pundit. Evaluating I/O Characteristics and Methods for Storing Structured Scientific Data. In Proceedings of the 20th International Parallel and Distributed Processing Symposium (IPDPS), April 2006.
- Avery Ching, Kenin Coloma, and Alok Choudhary. Challenges for Parallel I/O in GRID Computing. In Engineering the Grid: Status and Perspective, American Scientific Publishers, 2006.
- Wei-keng Liao, Alok Choudhary, Kenin Coloma, Lee Ward, Eric Russell, and Neil Pundit. MPI Atomicity and Concurrent Overlapping I/O. Book chapter 10 in High Performance Computing: Paradigm and Infrastructure, pp. 203 -- 218, John Wiley & Sons Inc. November 2005.
- Wei-keng Liao, Kenin Coloma, Alok Choudhary, and Lee Ward. Cooperative Write-behind Data Buffering for MPI I/O. In the Proceedings of the 12th European Parallel Virtual Machine and Message Passing Interface Conference (EURO PVM/MPI), Sorrento (Naples), Italy, September 2005.
- Wei-keng Liao, Kenin Coloma, Alok Choudhary, Lee Ward, Eric Russell, and Sonja Tideman. Collective Caching: Application-aware Client-side File Caching. In the Proceedings of the 14th IEEE International Symposium on High Performance Distributed Computing (HPDC-14), pp. 81-90, Research Triangle Park, NC, July 2005.
- Kenin Coloma, Alok Choudhary, Wei-keng Liao, Lee Ward, and Sonja Tideman. DAChe: Direct Access Cache System for Parallel I/O. In the Proceedings of the International Supercomputer Conference, Heidelberg, Germany, June 2005.
- K. Coloma, A. Choudhary, A. Ching, W. Liao, S. W. Son, M. Kandemir, and L. Ward. Power and Performance in I/O for Scientific Applications. In the Proceedings of the Next Generation Software (NGS) Workshop held in conjunction with International Parallel and Distributed Processing Symposium, April 2005.
- Kenin Coloma, Alok Choudhary, Wei-keng Liao, Lee Ward, Eric Russell, and Neil Pundit. Scalable High-level Caching for Parallel I/O. In the Proceedings of the 18th International Parallel and Distributed Processing Symposium, New Mexico, April 2004.
- Wei-keng Liao, Alok Choudhary, Kenin Coloma, George K. Thiruvathukal, Lee Ward, Eric Russell, and Neil Pundit. Scalable Implementations of MPI Atomicity for Concurrent Overlapping I/O. In the Proceedings of International Conference on Parallel Processing (ICPP), Kaohsiung, Taiwan, October 2003.