
Northwestern University



High-Performance Data Management, Access, and Storage Techniques for Tera-scale Scientific Applications

Table of Contents:
Objectives:
To develop a scalable high-performance data management system that
will provide support for data management, query capability and high-performance
accesses to large datasets stored in hierarchical storage systems (HSS).
This data management system will provide the flexibility of databases for
indexing, searches,
management of objects, creating and keeping histories and trails of data
accesses, while providing high-performance access methods and optimizations
(pooled striping, pre-fetching, caching, collective I/O) for accessing
large-scale data objects found in scientific computations.
Problem Description:
Management, storage, efficient access and analysis of 100's of GBs to 100's of
TBs of data, that is likely to be generated and/or used in various phases of
large-scale scientific experiments and simulations, such as those in
ASCI
application domains, are extremely challenging tasks.
Current data management and analysis techniques do not measure up to the
challenges posed by such large-scale requirements in term of performance,
scalability, ease of use and interfaces.
Tera-scale computing requires newer models and approaches to solving the
problems in storing, retrieving, managing, sharing, visualizing, organizing
and analyzing data at such a massive scale.
Also, since problem solving in scientific applications requires collaboration
and usage of distributed resources, the problem of data management and storage
is further exacerbated.
In order to understand multiTeraFLOPs class simulations, users will need to be able to plan complex interrelated sets of supercomputing runs, track and catalog the data and meta data associated with each run, perform statistical and comparative analysis covering multiple runs and explore multivariate time-series data. All these works has to be done before the programming implementation of users' applications. Especially, in order to perform I/O operations efficiently, users are required to understand the underlying storage architectures and file layouts in storage systems. Such requirements present challenging I/O intensive problems and an application programmer may be overwhelmed if required to solve these problems.
Methodology:
Our approach tries to combine the advantages of file systems
and databases, while avoiding their respective disadvantages.
It provides a user-friendly programming environment which allows easy
application development, code reuse, and portability; at the same time,
it extracts high I/O performance from the underlying parallel I/O
architecture by employing advanced I/O optimization techniques like
data sieving and collective I/O.
It achieves these goals by using an active meta-data management system
(MDMS) that interacts with the parallel application in question as well as
with the underlying hierarchical storage environment.
The proposed programming environment has three key components:
- user applications;
- meta-data management system; and
- hierarchical storage system.
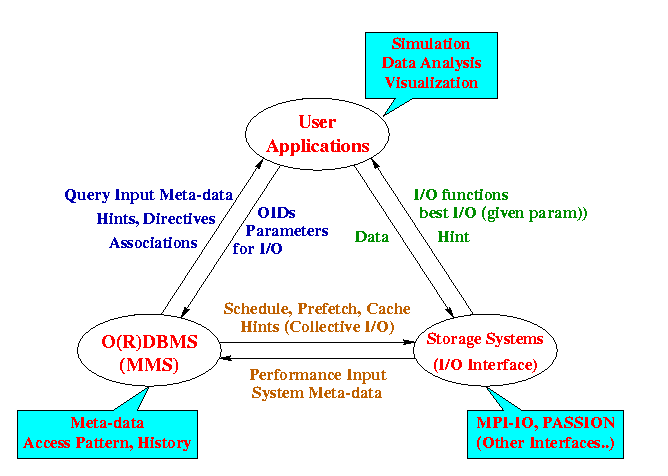
Figure 1. Three-tiered architecture. Each site can be located distributedly and connect with each other remotely through TCP/IP.
Normally, application programmers have to deal with the storage systems directly, shown as the two ovals, User Applications and Storage System, in Figure 1. Programmers are required to understand the interfaces of storage systems in which the files reside and the associated meta data that describes the internal structures of those files, such as file locations, names of datasets in each file, data structures, types, storage patterns, etc. The information is most likely written in separate text-format files, e.g. README, by the authors who created those data files. Sometimes, programmers even have to inquire additional information from the authors. Traditionally, these work can only be done by the users prior to programming their applications.
In this project, we add the third oval, a meta-data management system, into the figure which acts as an active middle-ware between users' applications and storage systems. This meta-data management system provides users a uniform interface to access resource and information in a heterogeneous computing environment. Through the user interfaces, users can inquire the meta data associated to the desired datasets or files. The inquired meta data not only can be used to make programming decisions at developing time but also can be used to determine condition branches at program's run time. In addition, the interface provides high-performance I/O subroutines that internally perform aggressive I/O operations in term of parallel collective/non-collective I/O and data pre-fetching in the hierarchical storage devices. The design and implementation of this high-performance meta-data management system focus on three aspects:
Meta-data management
In order to provide high-performance access to data in HSS, the first step is to determine what level of meta data of the scientific applications is essential for underlying high-performance implementation. Typically, three levels of meta data are considered:- Application level -- The information describing users' applications may contains the time of each run to keep track of the data usage, application execution environments, run-time arguments, comments, result summary, and timing results, etc. These historical meta data are important for optimizing the I/O operations (e.g. data pre-fetching in the HSS) for the future of data access.
- Program level -- This level of meta data mainly describes the structures of data used in users' applications, including data types, data structures, file locations, offsets of multiple data sets within files, single data set distributed across multiple files, and etc. These hints can provide easy-use interfaces for accessing the data.
- Performance level -- Two I/O performance concerns are determining parallel I/O calls on parallel file system and data access prediction to move data to the higher storage devices in HSS. Using MPI-IO, the parallel I/O calls can be either collective or non-collective depending on the data storage pattern and the partition pattern in the processors. The meta data in this level can be data partition pattern, data set association, data storage pattern, file storage striping factors, historical performance factors, and etc. These informations are used to provide hints of performing data pre-fetching, pre-staging, caching, and sub-filing.
Application programming interface
There are two types of application programming interfaces (API) provided by this system. One is for inquiring the meta data resided in the database. Users can use the inquired meta to understand the current status of the database by incorporating this type of APIs into an interactive graphic user interface (GUI) so that users can choose the best partition or data access strategies while programming their parallel applications. For dynamic programming purpose, these APIs can also be used in the applications to inquire meta data at the run time and make branch decision accordingly.Development of high-performance data access strategy
Data access performance improvement can be achieved from two aspects: choosing optimal I/O calls and prediction of data access. The optimal I/O calls mainly deal with the parallel I/O operations using underlying file disk system. When the way data partitioned among multiple processors is different from the data's storage pattern, choosing the right I/O calls affects the I/O performance significantly. On the other hand, tera-scale scientific applications usually manipulate massive amount of data which need to be stored in secondary storage devices, e.g. tapes. Data movement within hierarchical storage devices involves mechanical actions and costs a much larger overhead than between the processors and memory. Therefore, data access prediction becomes important for the data management system to retrieve tape resident data efficiently.- Data movement between memory and disk file system --
Recently, parallel file systems emerge and provide fast data access
techniques by striping files into multiple disks and, therefore,
I/O performance is improved by accessing multiple disks simultaneously.
However, the difference between partition and storage patterns can
introduce overhead of non-optimal I/O operations no matter a parallel
or traditional file system is used.
It is users' responsibility to match the two patterns and choose
the appropriate I/O calls in order to prevent this overhead.
Figure 4 shows several partition patterns for
a two-dimensional array by 4 processors.
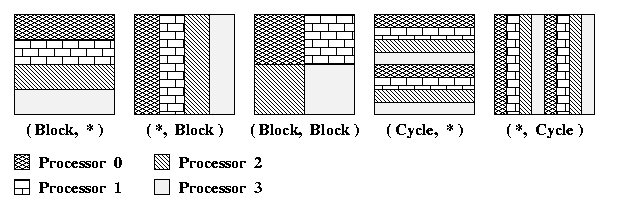
Figure 4. Different partition patterns for a 2-dimensional array partitioned by 4 processors.
The I/O interfaces of our system are built on top of MPI-IO, since MPI-IO is becoming a de facto standard for high-performance I/O systems. Our internal implementations focus on providing hints of optimal collective/non-collective I/O calls, setting file views for individual processors, associating data sets that have the same partition pattern, pre-fetching data from disk file systems, and data caching. Through inquiring meta data from the database, these optimal parallel I/O operations can be achieved.
- Data movement between disk and tape systems -- The sub-filing strategy stores a multi-dimensional tape-resident global array as a number of small chunks, called sub-files, which is transparent to the programmers. The main advantage of doing so is that the data requests for relatively small portions of the global array can be satisfied without transferring the entire global array from tape to disk as is customary in many hierarchical storage management systems.
- From historical access trails -- Since the data management system is designed to record all the actions of data access, a historical tail can be used to perform sub-files movement with the hierarchical storage devices. All sub-files for an array will be associated to some probability values indicated previous access trail and, naturally, this information becomes very important to decide the next sub-files to be moved within HSS in advance.
- Access hint provided by users -- Hints provided by users prior to each run can bring different factors to the data access prediction and help improve the performance. For example, users can specify either the data will be access in temporal (movie slides) or spatial (regional display) contiguity. These hints combined with the historical data access factors will be used together to predict which sub-files are most likely be accessed next.
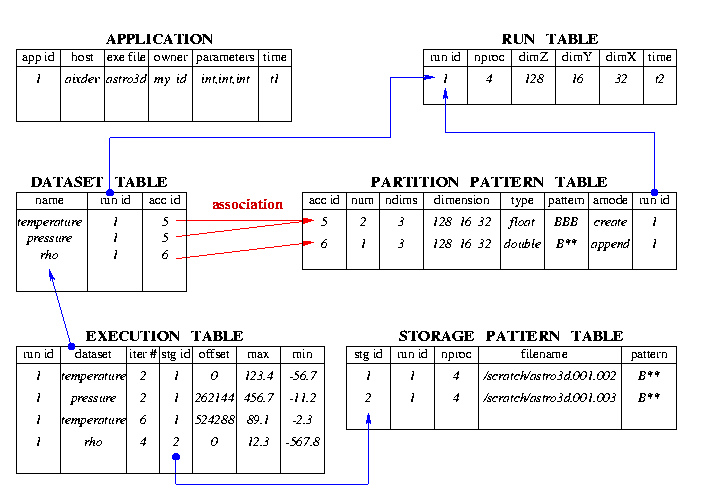
Figure 2. Meta-data representation in database system.
We use a relational database to manage these meta data by organizing them into database tables (relations.) Figure 2 shows the contents of the tables and their relations in our on-going implementation. There is one application table which contains all registered applications in our management system. For each registered application, it has five associated tables: run table, dataset table, partition pattern table, execution table, and storage pattern table. For example, datasets (arrays) may have the same partition pattern and are associated together. Since the data access to these datasets is very similar, the operations performed on one dataset are most likely re-used by other associated datasets. This, therefore, leaves hints for performance improvements.
The other type of APIs is for performing parallel I/O operations optimally. Current parallel file systems and parallel I/O libraries contain an excessive number of functions for different partition strategies. It is the task of users to choose the ones that match both processor partition and file partition. Our APIs are designed to reduce these programming burden from the users. Only the application side of information is needed, such as data set structures, data set names, application names, processor partition pattern, and these are no more than basic requirement information for users programming applications. Since the storage side of the meta data has been saved in the database, optimal parallel I/O calls can, then, be determined internally by our management system. Figure 3 gives a typical example of using this type of APIs in the applications.
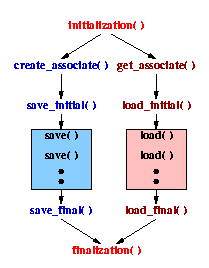
Figure 3. Execution flow of applications using our system's APIs.
Figure 5 illustrates the data movements in the HSS. When sub-file access pattern is predictable, these movements is performed internally in the management system to access data more efficiently. Furthermore, asynchronous I/O user interfaces will be implemented in the HSS to overlap the I/O operations for multiple sub-file accesses.
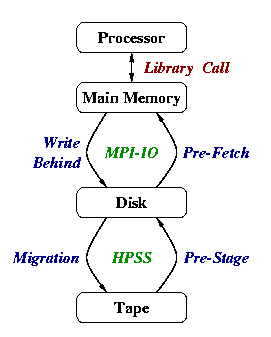
To find out the data access pattern for a specific data set becomes very important for designing the data management system. Usually, there are two ways to obtain this information:
Project Milestones:
- Mar. 2000 --
- Design and implement I/O optimization strategies on accessing tape resident data from remote hosts through SRB interface. These I/O optimizations include collective I/O, data sieving, subfile, superfile, SRB container. The functionalities of performing data staging, purging, and migration on the SDSC HPSS system were investigated. Since the HPSS native interface and MPI-IO interface are not available to general users, the implementation of access tape resident data was done through SRB interface.
- A system for accessing data from heterogeneous storage environment is proposed and investigated. Since SRB provides uniform programming interface to many storage the I/O interface of our system will be built on top of SRB to connect the host that runs the applications and the remote host that stores the data.
- A model of I/O performance prediction is investigated. This model uses historic I/O bandwidth performance numbers to provide hints for future I/O operations to different storage systems.
- The performance results of the work at this stage are presented in two papers submitted to ICPP 2000 and HPDC 2000, respectively.
- Nov. 1999 --
- Identify the control and data flow of the management system. Design the APIs for users' parallel applications to perform I/O operations on IBM SP PIOFS file system. The main efforts focus on I/O optimization of data movement between memory and parallel file disk system.
- Preliminary implementation of the Java GUI was designed and implemented to illustrate the idea of the operations of the whole management system. A demo was presented in the Research Exhibit in the SuperComputing Conference, 1999. The idea of design a demo program is described in the demo page which also includes the screen dumps of the Java GUI actural implemented.
- Aug. 1999 --
- Identify the meta data which is essential to stored in the management system and its representation in the database. The management system is implemented using PostgreSQL database.
- Design a sub-filing strategy for large multi-dimensional tape-resident data. The APIs are implemented on top of HPSS and MPI I/O where SRB is used to access the files in HPSS.
Publications:
- X. Shen and A. Choudhary. "A Distributed Multi-Storage I/O for Data Intensive Scientific Computing", in Journal of Parallel Computing, Volume 29, Issues 11-12, pp. 1623-1643, November-December 2003
- X. Shen, A. Choudhary, C. Matarazzo and P. Sinha. "A Multi-Storage Resource Architecture and I/O Performance Prediction for Scientific Computing", in Journal of Cluster Computing, Volume 6, Issue 3, pp. 189-200, July 2003.
- X. Shen, W. Liao, A. Choudhary, G. Memik, and M. Kandemir. "A High Performance Application Data Environment for Large-Scale Scientific Computations", in IEEE Transaction on Parallel and Distributed System , Volume 14, Number 12, pp. 1262-1274, December 2003.
- Y. Liu, W. Liao, and A. Choudhary. "Design and Evaluation of a Parallel HOP Clustering Algorithm for Cosmological Simulation", in the Proceedings of International Parallel and Distributed Parallel Processing (IPDPS), Nice, France, April 2003.
- X. Shen, and A. Choudhary. "MS-I/O: A Distributed Multi-Storage I/O System", in IEEE International Symposium on Cluster Computing and the Grid (CCGrid), Berlin, Germany, May, 2002.
- G. Memik, M. Kandemir, and A. Choudhary. "Design and evaluation of smart-disk cluster for DSS commercial workloads", in Journal of Parallel and Distributed Computing, Special Issue on Cluster and Network-Based Computing, Volume 61, Issue 11, pp. 1633-1664, 2001.
- X. Shen, and A. Choudhary. "DPFS: A Distributed Parallel File System", in IEEE 30th International Conference on Parallel Processing (ICPP) , Valencia, Spain, September, 2001.
- X. Shen, W. Liao, and A. Choudhary. "An Integrated Graphical User Interface For High Performance Distributed Computing" in Proc. International Database Engineering and Applications Symposium (IDEAS), Grenoble, France, July, 2001.
- J. No, R. Thakur, D. Kaushik, L. Freitag, and A. Choudhary. "A Scientific Data Management System for Irregular Applications", in Proc. of the Eighth International Workshop on Solving Irregular Problems in Parallel (Irregular 2001), April 2001
- X. Shen, W. Liao, and A. Choudhary. "Remote I/O Optimization and Evaluation for Tertiary Storage Systems through Storage Resource Broker", in IASTED Applied Informatics, Innsbruck, Austria, February, 2001.
- W. Liao, X. Shen, and A. Choudhary "Meta-Data Management System for High-Performance Large-Scale Scientific Data Access", in the 7th International Conference on High Performance Computing, Bangalore, India, December 17-20, 2000
- J. No, R. Thakur, and A. Choudhary, "Integrating Parallel File I/O and Database Support for High-Performance Scientific Data Management", in Proc. of SC2000: High Performance Networking and Computing, November 2000.
- X. Shen and A. Choudhary. "A Distributed Multi-Storage Resource Architecture and I/O Performance Prediction for Scientific Computing", in International Symposium on High Performance Distributed Computing, Pittsburgh, Pennsylvania, August 1-4, 2000.
- X. Shen, W. Liao, A. Choudhary, G. Memik, M. Kandemir, S. More, G. Thiruvathukal, and A. Singh. "A Novel Application Development Environment for Large-Scale Scientific Computations", in International Conference on Supercomputing, Santa Fe, New Mexico, May, 2000.
- X. Shen, G. Thiruvathukal, W. Liao, and A. Choudhary. "A Java Graphical User Interface for Large-Scale Scientific Computations in Heterogeneous Systems", in HPC-ASIA, May, 2000.
- A. Choudhary, M. Kandemir, J. No, G. Memik, X. Shen, W. Liao, H. Nagesh, S. More, V. Taylor, R. Thakur, and R. Stevens. "Data Management for Large-Scale Scientific Computations in High Performance Distributed Systems", in Cluster Computing: the Journal of Networks, Software Tools and Applications, Volume 3, Issue 1, pp. 45-60, 2000.
- G. Memik, M. Kandemir, and A. Choudhary. "APRIL: A Run-Time Library for Tape Resident Data", in the 8th NASA Goddard Space Flight Center Conference on Mass Storage Systems and Technologies and 17th IEEE Symposium on Mass Storage Systems , March, 2000.
- A. Choudhary, M. Kandemir, H. Nagesh, J. No, X. Shen, V. Taylor, S. More, and R. Thakur. "Data Management for Large-Scale Scientific Computations in High Performance Distributed Systems", in High-Performance Distributed Computing Conference'99, San Diego, CA, August, 1999.
- A. Choudhary and M. Kandemir. "System-Level Metadata for High-Performance Data management", in IEEE Metadata Conference, April, 1999.
Project Team Members:
| Prof. | Alok Choudhary | (P.I.) |
| Prof. | Valerie Taylor | (Co. P.I.) |
| Prof. | George Thiruvathukal | |
| Prof. | Wei-keng Liao | |
| Graduate Student | Xiaohui Shen | |
| Graduate Student | Gokhan Memik | |
| Undergraduate Student | Arti Singh |