
Sponsor:
Advanced Scientific Computing Research (ASCR) under the U.S. Department of Energy Office of Science (Office of Science)
Project Team Members:
Northwestern University
The HDF Group
- Quincey Koziol
- Gerd Herber
Argonne National Laboratory
North Carolina State University
- Nagiza Samatova
- Sriram Lakshminarasimhan



DAMSEL - A Data Model Storage Library for Exascale Science
Overview
Parallel computational science applications have been described in terms of computation and communication patterns. An early taxonomy was the so-called seven dwarfs, later expanded to 13 (Table 1 below). Description of a parallel program in terms of patterns has continued along two primary paths, the Berkeley pattern language and the parallel patterns developed by Ralph Johnson (one of the gang of pioneering the description of design patterns). The taxonomy represented by these patterns describes the operations performed by typical simulations quite well, and petaFLOPS rates of computation have been demonstrated across a wide range of these computational motifs. However, high FLOPS rates are only part of achieving breakthrough science using computation. High I/O performance is critical from a performance and productivity perspective, to support interpretation of computational results and operation of these codes at fidelities enabled by extreme-scale computers. Codes across the range of computational motifs are finding it difficult to perform I/O on s petascale architectures, and this I/O problem may limit those ability to achieve exascale performance.

The design of high-level I/O libraries is in need of update. Figure 1 (below) shows aggregate read and write rates from a recent I/O study on the IBM Blue Gene/P system at the Argonne Leadership Compute Facility (ALCF). We see that highly synthetic workloads such as IOR attain a high fraction of peak write bandwidth, as does the explicit out of core (OOC) Madbench2, an MPI-IO based code. Unfortunately, the benchmarks that more accurately represent I/O from applications (BTIO and Flash I/O) are only able to attain around 40% of peak, and sometimes they are much lower performing. Read performance is similarly low. This performance gap has not prevented science discoveries thus far, but as the gap between compute and storage capabilities continues to widen, applications must be able to extract all the performance available from the storage hardware.
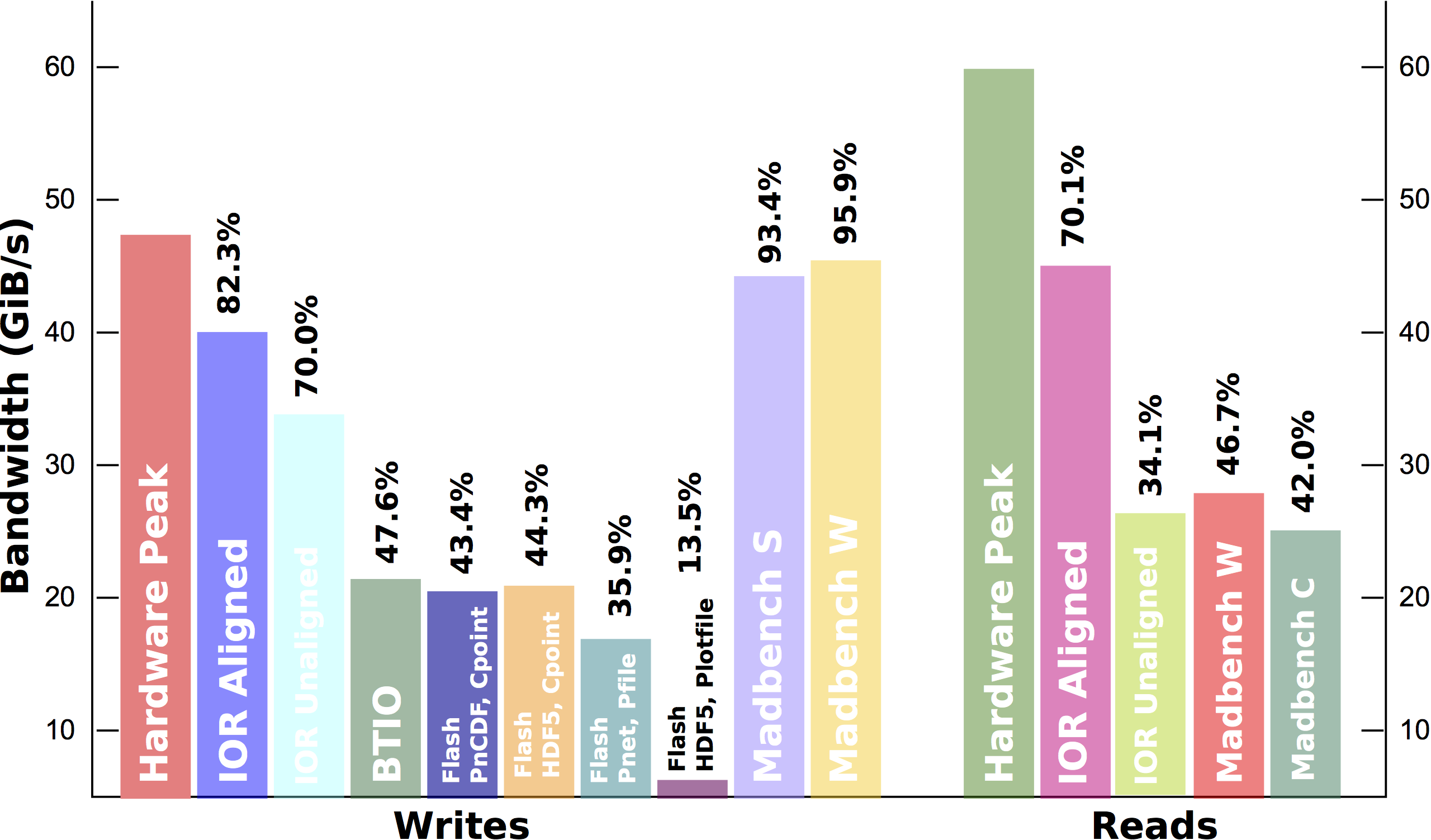
Figure 1. Comparison of performance for a number of application benchmarks on the ALCF IBM BG/P system.
Although high-level I/O libraries have made an important contribution to supporting large parallel applications, they do not always attain a high percentage of peak performance when used from these applications. The reasons, among others, have been that (1) the underlying models, formats, and APIs in storage software did not explicitly consider parallelism in their original designs, (2) the parallelism subsequently introduced has been incremental and has often been driven to work around limitations of interfaces and underlying software (e.g., working around a specific file system performance bug), and (3) many more applications require, for scalability and algorithmic reasons, much more sophisticated data structures than what the original designs had incorporated (e.g., adaptive meshes, irregular datasets).
The goal of Damsel project is to enable Exascale computational science aplications to interact conveniently and efficiently with storage through abstractions that match their data models. We are pursuing four major activities:- constructing a unified, high-level data model that maps naturally onto a set of data model motifs used in a representative set of high-performing computational science applicatons;
- developing a data model storage library, called Damsel, that supports the unified data model, provides efficient storage data layouts, incorporates optimizations to enable exascale operation, and is tolerant to failures;
- assessing the performance of this approach through the construction of new I/O benchmarks or the use of existing I/O benchmarks for each of the data model motifs; and
- productizing Damsel and working with computational scientists to encourage adoption of this library by the scientific community.
Data Model
- A set of new data models, inspired by MOAB/ITAPS
- Support for unstructured and structured mesh
- Entity, blocks
- Grouping relationships
- Entity sets, with parent/child relations
- Variables and sttributes
- sparse, dense tags
- Describing physical domain
- Units, dimensions
Terms and concepts used in Damsel is described here.
More detailed description of Damsel data model is here.
Usecases
- Simple 2D
- FLASH
- NASA Grid
- Community Atmosphere Model (CAM)
- Computational Fracture Mechanics (CFM)
- Subfiling
- Usecases for Damsel APIs
User Documents
Download Source Codes
- The current stable version: